Bostadsformedlingen improved (webscraping)
Continuation of Bostadsformedlingen improved (authentication).
After authenticating on Bostadsformedlingen there’s potentially a lot of useful data that can be utilized or at least make the process of deciding which apartments to apply for much easier. For one, AllaAnnonser comes with a field KanAnmalaIntresse (“Can Apply”) which takes the value true if you’re eligible to apply for the apartment. Note that this field is only populated with true values if you’re logged in, otherwise it will always be false.
One of the more useful pieces of information that could be utilized when logged in is position in the queue you would have in the case of applying. Unfortunately this information does not come with AllaAnnonser, however, it’s presented on the detail page of each listing in the div class col40. Thus we have to resort to some webscraping.
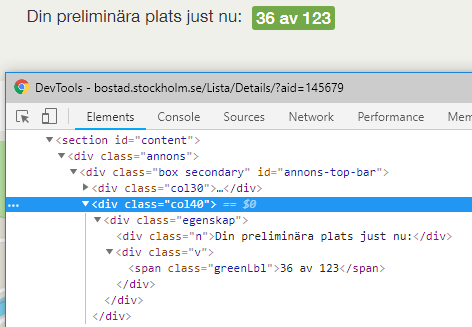
The basic idea is to iterate over all of the current listings and for each page parse col40 using the library bs4 and parse the html page using BeautifulSoup. Then we can extract the queue by calling get_text() on the div class v. To download each page the URL is constructed using the listing id and subsequently GETing the content using the same session that was used for authentication.
from bs4 import BeautifulSoup
def extract_queue(html):
soup = BeautifulSoup(html, 'html.parser')
property = soup.find(class_='col40').find(class_='egenskap')
if property is None:
queue = nan
else:
queue = property.find(class_='v').get_text().replace(' av ', '/')
return queue
def download_html(session, id, relevant):
q = nan
if relevant is True:
url = 'https://bostad.stockholm.se/Lista/Details/?aid=%s' % id
response = session.get(url)
if response.status_code == 200:
q = extract_queue(response.text)
print('Downloaded queue(%s) for id: %s' % (q, id))
return q